
One of the problems to master when scraping the web is to overcome server side limitation, like a maximum result count. In this article I will explain how you can use the geoiter package for python to fractal your queries to get the most from a search engine. I also show how you can shift you sync httpx client to a async client issuing all request at one time.
Problem
For example you will tackle a site like this:
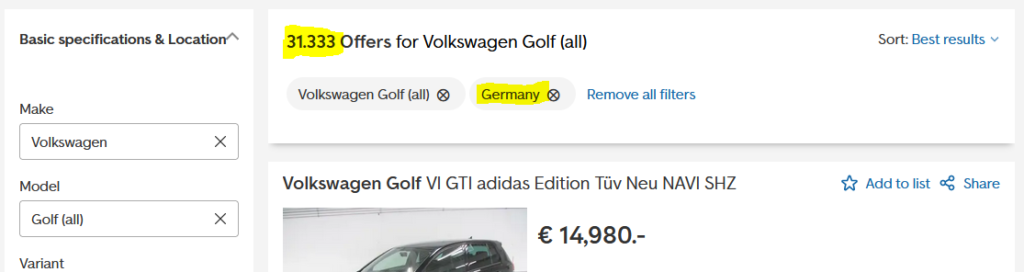
Lets say we want to have all the 31.333 quotes of VW Golf in Germany. What we will first try is to use the pagination of the webpage.
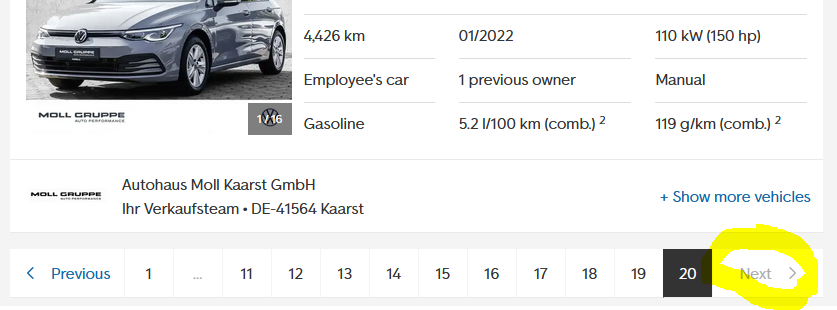
Webpages with possible large datasets will limit the actual result count somehow. In this case here the webpage does not allow more than 20 pages giving us a maximum of 400 car quotes.
Because we like to have all the offers and don’t like to curtail the results through other filter properties we need to find a solution to fractal that 30.000 big query to smaller ones.
Trivial Solution
A trivial solution here could be to manipulate the query parameters of the uri like ...powertype=kw&search_id=1iwndnshvga&page=21
But this will not work here. The server will reply with a html file which is saying 0 results.
Solution
The actual solution is also simple. To fractal the query into smaller sized queries which will fit into the 20×20 limit of the webpage we will use geoiter package for python.
Geoiter provides a quite simple interface for scraping purposes. It gives you an iterator which yields midpoints coordinates in a given boundary. No worries, its not that complicate.
pip install geoiterFirst we simple install geoiter from pypi with pip. You can also download the source from github.
Lets start with a rather simple code utilizing the example data provided with the package.
# main.py
from geoiter.util.ressource_example import get_german_border
# this is a example list of coordinates. You may get you own from open street map or other geospatial services.
from geoiter import GeoIter
german_border = get_german_border
gi = GeoIter(
boundary=german_border,
radius=100,
comp_rate=20
)
midpoints = list(gi) # consume that iterator at once
print(len(midpoints), midpoints)
# prints:
# 18 [(54.184302636275454, 10.4540982), (54.14901311305548, 7.535786698090457), ...]Now we have divided Germany into 18 circles. This will give us 60.000 / 18 = 3.333 results. This is still to big. So we use some math: 30.000 / 400 = 150. So we will need to divide Germany into 150 circles approximately. The radius for this is around 30 km.
Lets program a simple web scraper eating all 30.000 car quotes.
# main.py
import math
import httpx # or any other popular http client.
from lxml.html import fromstring # or use bs4
from geoiter.util.ressource_example import get_german_border
# this is a example list of coordinates. You may get you own from open street map or other geospatial services.
from geoiter import GeoIter
german_border = get_german_border()
# we keep a reference here
query_radius = 30
gi = GeoIter(
boundary=german_border,
radius=query_radius,
comp_rate=20
)
midpoints = list(gi) # consume that iterator at once
print(len(midpoints), midpoints[:2])
base_url = r"https://www.autoscout24.com/lst/volkswagen/golf-(" \
r"all)?sort=standard&desc=0&atype=C&ustate=N%2CU&powertype=kw "
def parse_offers(body_tree):
# prints the results of one html page with max. 20 offers
articles = body_tree.xpath("//article")
for article in articles:
title = article.xpath(".//h2/text()")[0]
price = article.xpath(".//p/text()")[0]
print(title, price)
def main():
# here we limit the coordinates just for demo purposes.
for coordinate in midpoints[100:102]:
query_url = f"{base_url}&lon={coordinate[1]}&lat={coordinate[0]}&zipr={query_radius}"
response = httpx.get(query_url)
assert response.status_code == 200
body_tree = fromstring(response.text)
query_size = body_tree.xpath("//div[@class='ListHeader_top__jY34N']/h1/span/span/text()")[0]
if query_size:
parse_offers(body_tree)
more_pages = int(query_size) // 20
print(f"I need to scrape now {query_size} offers or {more_pages} more page(s).")
for page in range(1, more_pages + 1):
response = httpx.get(query_url + f"&page={page + 1}")
body_tree = fromstring(response.text)
parse_offers(body_tree)
if __name__ == '__main__':
main()
This runs very well and has less than 50 lines of code. I would say this is why python is most loved language in the world. Beautiful, readable and simple.
But as there will be a lot of more server requests (when doing the complete scrape) we should think how we could get more performance. httpx packages brings also an async client with it. We can simply run the client with pythons async framework. Of course we need to rearrange and refactor a little bit.
# main.py
import asyncio
import httpx # or any other popular http client.
from lxml.html import fromstring # or use bs4
from geoiter.util.ressource_example import get_german_border
# this is a example list of coordinates. You may get you own from open street map or other geospatial services.
from geoiter import GeoIter
german_border = get_german_border()
query_radius = 30
gi = GeoIter(
boundary=german_border,
radius=query_radius,
comp_rate=20
)
midpoints = list(gi) # consume that iterator at once
print(len(midpoints), midpoints[:2])
base_url = r"https://www.autoscout24.com/lst/volkswagen/golf-(" \
r"all)?sort=standard&desc=0&atype=C&ustate=N%2CU&powertype=kw "
def parse_offers(body_tree):
articles = body_tree.xpath("//article")
for article in articles:
title = article.xpath(".//h2/text()")[0]
price = article.xpath(".//p/text()")[0]
print(title, price)
async def fetch_page(client, query_url):
response = await client.get(query_url)
body_tree = fromstring(response.text)
parse_offers(body_tree)
async def fetch_query_coro(client, query_url, loop):
response = await client.get(query_url)
assert response.status_code == 200
body_tree = fromstring(response.text)
query_size = body_tree.xpath("//div[@class='ListHeader_top__jY34N']/h1/span/span/text()")[0]
if query_size:
parse_offers(body_tree)
more_pages = int(query_size) // 20
print(f"I need to scrape now {query_size} offers or {more_pages} more page(s).")
pending = set()
for page in range(1, more_pages + 1):
pending.add(
loop.create_task(fetch_page(client, query_url + f"&page={page + 1}"))
)
done, pending = await asyncio.wait(pending)
async def main():
client = httpx.AsyncClient()
loop = asyncio.get_event_loop()
async with client:
pending = []
for coordinate in midpoints[100:102]:
query_url = f"{base_url}&lon={coordinate[1]}&lat={coordinate[0]}&zipr={query_radius}"
pending.append(
loop.create_task(fetch_query_coro(client, query_url, loop))
)
done, pending = await asyncio.wait(pending)
if __name__ == '__main__':
asyncio.run(main(), debug=True)
Yes indeed, we do not need even one synchronization paradigm. Writing above program n the threaded world we need to use at least a queue and several workers to get the same performance. If you want to learn more about the superpowers of asynchronous programming visit my post here.